sigmoid神经元
学习算法是如此NICE的东西,但问题来了:我们该如何为神经网络量身设计一种学习算法呢?现在假设有一个由感知机构成的网络,我们想让这个网络学习如何去解决一些问题。举例来说,对于一个以手写数字的扫描图像的原始像素数据作为输入的网络,我们想要这个网络去学习权值(weights)和偏置(biases)以便最终正确地分类这些数字。为了说明学习算法如何才能有效,我们首先假设在网络的一些权值(或偏置)上做一个小的改变。我们期望的结果是,这些在权值上的小改变,将会为网络的输出结果带来相应的改变,且这种改变也必须是轻微的。我们在后面将会看到,满足这样的性质才能使学习变得可能。下面的图片反映了我们想要的结果(当然,图示的网络非常简单,它并不能被用来做手写数字识别)。
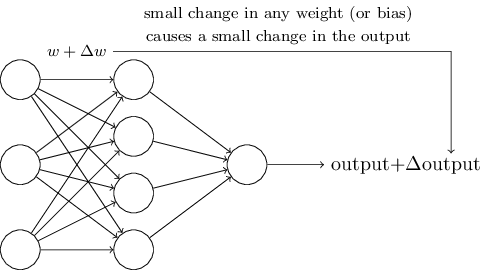
如果满足在权值(或偏置)上的小改变只会引起输出上的小幅变化这一性质,那么以此性质为基础,我们就可以改变权值和偏置来使得网络的表现越来越接近我们预期。例如,假设原始的网络会将一张写着「9」的手写数字图片错误分类为「8」。我们可以尝试找到一个正确的轻微改变权值和偏置的方法,来使得我们网络的输出更接近于正确答案——将该图片分类为「9」。重复这个过程,不断地修改权值和偏置并且产生越来越好的结果。这样我们的网络就开始学习起来了。
但问题在于,当我们的网络包含感知机时情况就与上述描述的不同了。事实上,轻微改变网络中任何一个感知机的权值或偏置有时甚至会导致感知机的输出完全翻转——比如说从变为。 这个翻转行为可能以某种非常复杂的方式彻底改变网络中其余部分的行为。所以即使现在「9」被正确分类了,但网络在处理所有其他图片时的行为可能因一些难以控制的方式被彻底改变了。这导致我们逐步改变权值和偏置来使网络行为更加接近预期的学习方法变得很难实施。也许存在一些巧妙的方法来避免这个问题,但对于这种由感知机构成的网络,它的学习算法并不是显而易见的。
由此我们引入一种被称为S型(sigmoid ,通常我们更习惯使用它的英文称呼,所以本文的其他地方也将使用原始的英文)神经元的新型人工神经元来解决这个问题。sigmoid神经元与感知机有些相似,但做了一些修改使得我们在轻微改变其权值和偏置时只会引起小幅度的输出变化。这是使由sigmoid神经元构成的网络能够学习的关键因素。
好,接下来就开始介绍本节的主角了。我们将沿用感知机的方式来描述sigmoid神经元。

和感知机一样,sigmoid神经元同样有输入, , 但不同的是,这些输入值不是只能取或者,而是可以取到间的任意浮点值。所以,举例来说,对于sigmoid神经元就是一个合法输入。同样,sigmoid神经元对每个输入也有相应的权值,,以及一个整体的偏置, 。不过sigmoid神经元的输出不再是或,而是 , 其中的被称为sigmoid函数(sigmoid function)1,该函数定义如下:
将上述内容总结一下,更加准确的定义,sigmoid神经元的输出是关于输入,权值,和偏置的函数:
乍一看去,sigmoid神经元与感知机样子很不同。如果你对它不熟悉,sigmoid函数的代数形式看起来会有些晦涩难懂。但事实上,sigmoid神经元与感知机有非常多相似的地方。sigmoid函数的代数式更多地是展现了其技术细节,而不应是成为理解它的障碍。
为了理解sigmoid神经元与感知机模型的相似性,我们假设是一个很大的正数。这时且。即是说,当是一个很大的正数时,sigmoid神经元的输出接近于,与感知机类似。另一方面,当是一个绝对值很大的负数时,且。所以当是一个绝对值很大的负数时,sigmoid神经元的行为与感知机同样很接近。只有当是一个不太大的数时,其结果与感知机模型有较大的偏差。
我们不禁要问,的代数式到底有何含义?我们该如何地理解它呢?事实上,的确切形式并不是那么重要——对于我们理解问题,真正重要的是该函数画在坐标轴上的样子。下图表示了它的形状:

这个形状可以认为是下图所示阶梯函数(step function)的平滑版本:
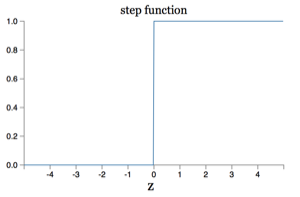
如果把函数换成阶梯函数,那么sigmoid神经元就变成了一个感知机,这是因为此时它的输出只随着的正负不同而仅在或这两个离散值上变化2。所以如前面所言,当使用函数时我们就得到了一个平滑的感知机。而且,函数的平滑属性才是其关键,不用太在意它的具体代数形式。函数的平滑属性意味着当我们在权值和偏置上做出值为,的轻微改变时,神经元的输出也将只是轻微地变化。事实上,由微积分的知识可知,近似于:
其中求和运算是将所有的权值相加,和表示分别求对和的偏导。如果你看着偏微分不开心,不要惊慌,上面的公式虽然看起来有些复杂,但其实其中的偏微分非常简单(好消息~):是关于权值和偏置的改变量和的线性函数(linear function)。这种线性属性,使得选择权值和偏置的轻微改变量并使输出按照预期发生小幅度变化成为易事。由上可知,sigmoid神经元不仅与感知机有很多相似的性质,同时也使描述「输出怎样随权值和偏置的改变而改变」这一问题变得简单。
如果真的只是的形状起作用而其具体代数形式没有什么用的话,为什么公式(3)要把表示为这种特定的形式?事实上,在书的后面部分我们也会偶尔提到一些在输出中使用其它激活函数(activation function)的神经元。当我们使用其它不同的激活函数时主要改变的是公式(5)中偏微分的具体值。在我们需要计算这些偏微分值之前,使用将会简化代数形式,因为指数函数在求微分时有着良好的性质。不管怎样,在神经网络工作中是最常被用到的,也是本书中最频繁的激活函数。
我们该如何解释sigmoid神经元的输出呢?显然,感知机和sigmoid神经元一个巨大的不同在于,sigmoid神经元不仅仅只输出或者,而是到间任意的实数,比如,都是合法的输出。在一些例子,比如当我们想要把神经网络的输出值作为输入图片的像素点的平均灰度值时,这点很有用处。但有时这个性质也很讨厌。比如在我们想要网络输出关于「输入图片是9」与「输入图片不是9」的预测结果时,显然最简单的方式是如感知机那样输出或者。不过在实践中我们可以设置一个约定来解决这个问题,比如说,约定任何输出值大于等于的为「输入图片是9」,而其他小于的输出值表示「输入图片不是9」。当以后使用类似上面的一个约定时,我都会明确地说明,所以这并不会引起任何的困惑。
1 顺便提一句,有时也被称作逻辑斯谛函数(logistic function),对应的这个新型神经元被称为逻辑斯谛神经元(logistic neurons)。记住这些术语很有用处,因为很多从事神经网络的人都会使用这些术语。不过本书中我们仍然使用sigmoid这一称呼。
2 事实上,当时感知机将输出,但此时阶梯函数输出值为。所以严格来讲,我们需要修改阶梯函数在这个点的值。大家明白这点就好。
练习
sigmoid神经元模拟感知机(第一部分)
对一个由感知机组成的神经网络,假设将其中所有的权值和偏置都乘上一个正常数, , 证明网络的行为并不会发生改变。
sigmoid神经元模拟感知机(第二部分)
假设与上述问题相同的初始条件——由感知机构成的神经网络。假设感知机的所有输入都已经被选定。我们并不需要实际的值,只需要保证输入固定。假定对网络中任意感知机的输入都满足。现在将网络中所有的感知机都替换为sigmoid神经元,然后将所有的权值和偏置都乘上一个正常数 。 证明在极限情况即下,这个由sigmoid神经元构成的网络与感知机构成的网络行为相同。同时想想当时为何不是如此?